Spark Tuning for Data skewing and low parallelism.
![]()
Apache spark is the de facto tool for data engineering, you can confirm that just looking at the companies that trust Spark to handle their data engineering efforts.
But…
By the quantity of languages and types of applications spark can handle you can expect some difficulties to arise. And the main issues are related to Data Skew and Low Parallelism, and these are the issues we will focus now.
Defining the problems
-
Data Skew:

In Statistical terms a data skewing is refered to the value distribution that is or become uneven, as can be seen in the first image. Data skewing in computational systems for data processing normally is caused by transformations applied to the data. Some of these trasnformations are Join, groupBy and orderBy.

This situation often happens when you are trying to join tables that are not well distributed in the nodes of the cluster, this can make some partitions to become much higher than the others causing spark not to properly process the data in parallel. -
Low Parallelism: The spark processing will not fully use the cluster resources until the level of parallelism for each operation is high enough. For this reason, the main source of low level of parallelism is data skewing. We know that data skewing is directly connected to partitions and it cause low parallelism.

In the above example we can see that only 2 executors are processing 128 partitions even though there are 12 executors available but were not used to process the data. Low paralelism makes the time of the longer running stage be the bottleneck of the whole processing.
Identifying the problem
How to know if I have data skewness?
You can get evidences from:
- Running counts against the partitions of the dataframe;
- Verifying the Web UI of the SparkContext of your application and look for task and stages that are taking longer than the others to finish.
Running counts against the partitions of the dataframe
After you read the data to a dataframe called ‘df’ you can call the function spark_partition_id. This function when called determines the key(s) of the partitions in a dataframe. Find below an example command to find the number of partitions and plot it using jupyter notebooks:</div>
%python
df_partition_counts = df.groupBy(spark_partition_id()) \
.count() \
.orderBy(desc("count"))
You can see below an example output:

Verifying the Web UI and analyzing the size of data processed by stage/task or the time taken.
Other way to perform this analysis without the need to write and execute code is to look at the web UI of the application and analyze the tasks. After accessing the web UI you go to the Stages Tab. Stages for all jobs:
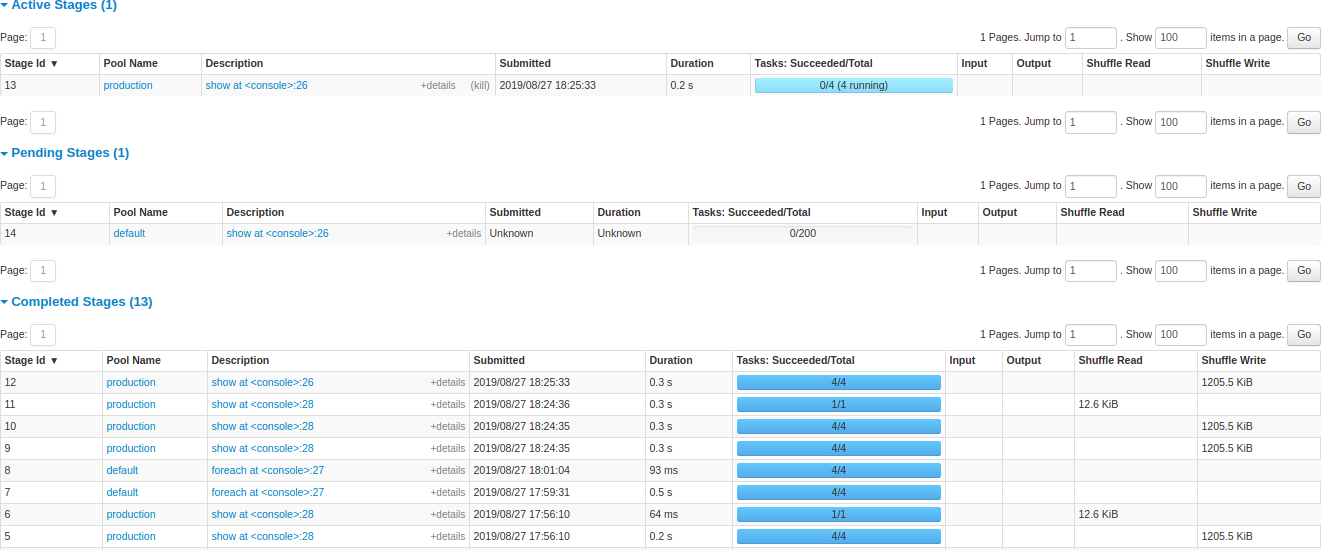
In the example below you can see that the first task is processing almost all the data alone, and does this at the risk of crashing the node and is the main cause for the long processing time.
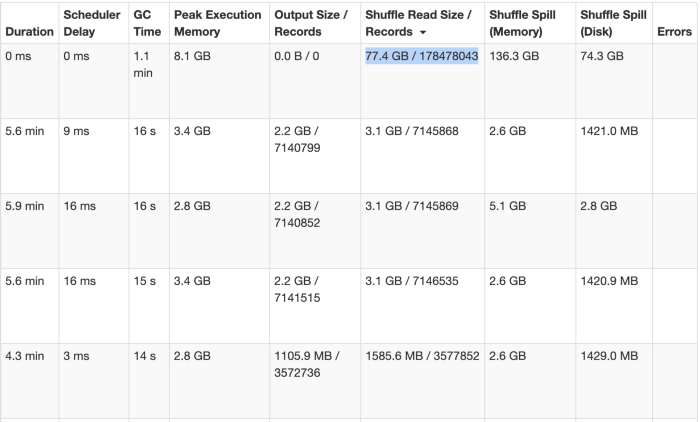
Another point that we can take from the last image is the relation between partitions and parallelism. When Spark read data and creates the RDD and it distributes the partitions across different nodes. One important way to increase parallelism of spark processing is to increase the number of executors on the cluster.
However, knowing how the data should be distributed, so that the cluster can process data efficiently is extremely important. Apache Spark manages data through RDDs using partitions which help parallelize distributed data processing with negligible network traffic for sending data between executors. By default, Apache Spark reads data into an RDD from the nodes that are close to it.
Solving the problem
Knowing that the Data Skewness and partitioning are related to each other we will tackle the data skewness problem and at the same time will solve the low parallelism issue.
- Enabling Adaptive Query Execution AQE
This feature is available since Apache Spark 3.0.0 and is enabled by default on Spark 3.2.0. When enabled in Spark SQL it makes use of the runtime statistics to choose the most efficient query execution plan. It is an optimization of the query execution plan made by the Spark Planner.spark.conf.set("spark.sql.adaptive.enabled", true) spark.conf.set("spark.sql.adaptive.skewJoin.enabled",true)The parameter spark.sql.adaptive.skewJoin.enabled does the following:
Spark dynamically handles skew in sort-merge join by splitting (and replicating if needed) skewed partitions.
To know more about AQE click here .
- Repartition Spark Dataframes
To be able to process data in parallel Spark needs to partition the data and distribute it across the executors. Assuming that you have 50 executors and 5 cores per executor, so you should have at least 70 x 8 = 560 partitions. By default, spark creates one partition for each HDFS block, and a HDFS block has 128 MB (Hadoop Version 2) and a task is created for each partition. Each executor is responsible for 1 partition. If you have 100GB of data ,or 100,000MB, dividing by the block size you will have, aproximately, 781 blocks/partitions. The ideal number of partitions based in executors and cores is 560. The ideal number of partitions based in block size is 780. Let’s stay with the higher partitions number because we will have partitions with less data to process and the Spark parallelism will take care of it. Having 780 partitions / 70 executors = 11 partitions per executor of 128mb per partition. If we go with 560 partitions / 70 executors = 8 partitions per executor of 178mb per partition. If initially your dataframe is created with a low number of partitions you increase it:df = df.repartition(780) print(df.rdd.getNumPartitions())But if your dataframe were created with too much partitions we can reduce it using:
df = df.coalesce(560) print(df.rdd.getNumPartitions()) -
Key Salting Sometimes you will have extremely huge datasets with many columns and billions of rows, and in this situation it is hard to find a good column for partitioning. In this situation we can make use of a technique called key salting, in this technique the idea is to invent a new key, which guarantees an even distribution of data.
See below a simple example of creation of key salting:
import pyspark.sql.functions as F df = df.withColumn('salt', F.rand()) df = df.repartition(8, 'salt')To check if the key salting you can run the command below:
df.groupBy(F.spark_partition_id()).count().show()Conclusion
When developing new applications always remember of:
- Scalability: Plan to different sizes of data volume;
- Reliability: Make tests to asure the solution you developed can handle many situations;
- Performance: Assess the time and consumption of resources to the best distribution of cluster resources;
- Maintainability: Keep it simple so it can be replicated and reused.
And with those basics ideas and solutions that I shared, your Spark applications will run satisfactorily.